|
| |||||||||||
|
Susanne Albers, Max-Planck-Institut für Informatik
1. Einführung
Die klassische Entwicklung und Analyse von Algorithmen geht davon aus,
daß die zur Lösung eines Problems benötigten Daten zu Beginn
der Berechnungen vollständig vorliegen. In vielen Anwendungen ist
diese Annahme jedoch unrealistisch. Algorithmische Probleme, die in der
Praxis auftreten, sind oftmals online, d.h. relevante Daten treffen
erst nach und nach im Laufe der Zeit ein. Ein Online-Algorithmus muß
Ausgaben berechnen, ohne zukünftige Eingaben zu kennen. Online-Probleme
treten in vielen Bereichen der Informatik auf, beispielsweise in der Ressourcenverwaltung
auf Betriebssystemebene, in verteilten Systemen, in der Robotik oder im
Bereich Datenstrukturen. Drei konkrete Probleme seien hier erwähnt,
auf die wir in diesem Artikel noch genauer eingehen werden.
Paging: Gegeben ist ein zweistufiges Speichersystem bestehend aus einem kleinen Speicher mit schnellem Zugriff und einem großen Speicher mit langsamen Zugriff. Welche Speicherseiten sollen in dem kleinen schnellen Speicher gehalten werden, wenn nicht bekannt ist, auf welche Seiten in der Zukunft zugegriffen wird?
Prozessorscheduling: Eine Folge von Jobs ist auf einer Menge von Prozessoren zu bearbeiten. Auf welchem Prozessor soll ein neu eintreffender Job eingeplant werden, wenn nicht bekannt ist, wie zukünftige Jobs aussehen?
Roboterexploration: Ein Roboter soll eine vollständige Karte einer unbekannten Umgebung mit möglichst geringer Wegstrecke erstellen. Wie soll der Roboter sich bewegen, wenn er die Umgebung erst beim Durchqueren kennenlernt?
Bei der Bewertung der Qualität eines Online-Algorithmus hat sich eine mathematische Analysetechnik entwickelt, die man kompetitive Analyse nennt. In einer kompetitiven Analyse wird ein Online-Algorithmus mit einem optimalen Offline-Algorithmus verglichen. Ein optimaler Offline-Algorithmus kennt alle Eingabedaten im voraus und kann eine optimale Lösung berechnen. Ein Online-Algorithmus A heißt c-kompetitiv, wenn für alle möglichen Eingaben die von A berechnete Lösung nicht schlechter als das c-fache einer optimalen offline berechneten Lösung ist.
Online-Algorithmen bilden seit gut zehn Jahren ein sehr aktives Forschungsgebiet innerhalb der theoretischen Informatik. Wir bearbeiten seit Anfang der neunziger Jahre zahlreiche Fragestellungen in diesem Bereich und stellen hier einige Ergebnisse vor.
2. Paging
Wir formulieren das Problem zunächst etwas präziser. In dem
zweistufigen Speichersystem haben alle Speicherseiten dieselbe Größe.
Das System muß eine Folge von Anfragen bedienen, wobei jede
Anfrage eine Seite im Speichersystem spezifiziert. Eine Anfrage kann unmittelbar
bedient werden, wenn die angefragte Seite im schnellen Speicher ist. Ist
die angefragte Seite nicht im schnellen Speicher, so tritt ein Seitenfehler
auf. Die fehlende Seite muß dann vom langsamen Speicher in den schnellen
Speicher geladen werden, damit die Anfrage bedient werden kann. Gleichzeitig
muß eine Seite aus dem schnellen Speicher entfernt werden, um Platz
für die neue Seite zu schaffen. Ein Pagingalgorithmus entscheidet,
welche Seite bei einem Fehler zu entfernen ist. Diese Entscheidung muß
dabei online, d.h. ohne die Kenntnis von zukünftigen Anfragen getroffen
werden. Ziel ist es, die Anzahl von Seitenfehlern, die beim Bedienen der
Anfragesequenz insgesamt erzeugt werden, zu minimieren.
Ein sehr bekannter und in der Praxis ausgezeichnet arbeitender Online-Pagingalgorithmus ist Least-Recently-Used (LRU). Bei einem Fehler entfernt der Algorithmus diejenige Seite aus dem schnellen Speicher, die am längsten nicht angefragt worden ist. Sleator und Tarjan [ST85] haben 1985 gezeigt, daß LRU k-kompetitiv ist, wobei k die Anzahl der Seiten ist, die gleichzeitig im schnellen Speicher gehalten werden können. Auf jeder Anfragesequenz ist die von LRU erzeugte Anzahl von Seitenfehlern also höchstens k-mal so hoch wie die von einem optimalen Offline-Algorithmus erzeugte Anzahl von Fehlern. Dieses Ergebnis war sehr bedeutend, weil Pagingalgorithmen zuvor nur auf von Wahrscheinlichkeitsverteilungen erzeugten Anfragesequenzen analysiert worden waren.
In einer unserer ersten Arbeiten haben wir die grundlegende Frage des Lookaheads in Online-Pagingalgorithmen untersucht: Welchen Vorteil hat ein Online-Algorithmus, wenn er nicht nur die aktuelle Anfrage sondern auch einige zukünftige Anfragen kennt? Wir konnten zeigen, daß man klassische Online-Pagingalgorithmen wie LRU so modifizieren kann, daß sie Lookahead ausnutzen und den kompetitiven Faktor von k schlagen. Eine einfache Modifikation von LRU arbeitet bei einem Seitenfehler wie folgt: Unter den Seiten, die nicht im Lookahead sind, entferne die Seite, die am längsten nicht angefragt worden ist. Dieser Algorithmus erzielt einen kompetitiven Faktor von k-l, wenn sich stets l paarweise verschiedene Seiten im Lookahead-Puffer befinden. Zusätzlich haben wir den Einfluß von Lookahead nicht nur für Paging sondern auch für eine Reihe anderer wichtiger Online-Probleme untersucht.
Unsere aktuellen Forschungsarbeiten beschäftigen sich mit verallgemeinerten Pagingproblemen, die in großen Netzwerken wie dem Internet auftreten. Dort haben Speicherseiten oder Dokumente (Textdateien, Bilder, Web-Seiten) unterschiedliche Größen und erzeugen unterschiedliche Kosten beim Laden. Ziel ist die Entwicklung beweisbar guter Online- und Offline-Strategien.
3. Prozessorscheduling
Wir betrachten eines der grundlegendsten Probleme in der Schedulingtheorie.
Gegeben sind p identische, parallel arbeitende Prozessoren. Eine
Folge von Jobs trifft ein. Jeder Job hat eine Bearbeitungszeit, die bei
Ankunft bekannt ist. Kommt ein neuer Job an, so muß er unmittelbar
auf einer der Prozessoren ohne die Kenntnis von zukünftigen Jobs eingeplant
werden. Zu minimieren ist der Makespan, d.h. das Bearbeitungsende
des letzten Jobs, der fertiggestellt wird. Der folgende elegante Schedulingalgorithmus,
der List genannt wird, erzielt einen kompetitiven Faktor von 2-1/p:
Plane einen neuen Job auf dem Prozessor ein, der aktuell die geringste
Last hat. Die Last eines Prozessors ist dabei definiert als die Summe der
Bearbeitungszeiten der bereits auf dem Prozessor eingeplanten Jobs. Eine
wichtige Frage war, ob ein kompetitiver Faktor erzielt werden kann, der
asymptotisch besser als 2 ist.

Vor zwei Jahren haben wir einen Algorithmus vorgestellt, der die zur Zeit beste Leistung erzielt. Idee des Algorithmus ist es, Belegungspläne zu vermeiden, in denen alle Prozessoren die gleiche Last haben. Haben alle Prozessoren die gleiche Last, so kann leicht ein kompetitiver Faktor von 2-1/p entstehen. Der neue Algorithmus hält zu jedem Zeitpunkt eine Menge M von p/2 Prozessoren mit einer geringen Last und eine Menge M’ von p/2 Prozessoren mit einer hohen Last. Ziel ist es, einen Belegungsplan aufrechtzuerhalten, in dem die gesamte Last auf Prozessoren in M nicht höher ist als 2/3 der gesamten Last auf Prozessoren in M’ (Abb. 1 zeigt ein ideales Lastprofil).
Jeder neue Job wird entweder auf dem Prozessor mit der geringsten Last in M oder auf dem Prozessor mit der geringsten Last in M’ eingeplant. Die Entscheidung, welcher der beiden Prozessoren gewählt wird, hängt von dem aktuellen Lastverhältnis in M und M’ ab. Der Algorithmus erzielt einen kompetitiven Faktor von etwa 1,9. Dies ist nicht wesentlich besser als 2. Jedoch können wir beweisen, daß kein Online-Algorithmus besser als 1,85-kompetitiv sein kann. Experimentelle Tests zeigen, daß der vorgestellte Algorithmus auch in der Praxis im allgemeinen besser als List ist.
4. Roboterexploration
In diesem Bereich sind sehr viele geometrische und graphentheoretische
Varianten untersucht worden. In einer grundlegenden geometrischen Variante
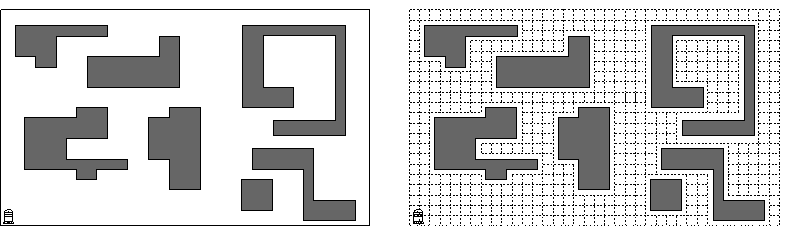
wird die Umgebung, in der der Roboter operiert, durch einen Raum mit polygonalen
Hindernissen modelliert (s. Abb. 2, linker Teil). Der Roboter hat einen
Sichtbereich von 360 Grad und kann beliebig weit in die Ferne schauen,
solange kein Hindernis die Sicht blockiert. Ziel ist es, einen möglichst
kurzen Pfad durch die Szene zu laufen, von dem aus jeder Punkt des Raumes
sichtbar ist.
Deng, Kameda und Papadimitriou [DKP98] haben einen n-kompetitiven
Algorithmus vorgestellt, der Räume mit n rechtwinkligen Hindernissen
exploriert. Sie vermuteten, daß ein Algorithmus mit einem konstanten
kompetitiven Faktor existiert. Zusammen mit einem Diplomanden haben wir
diese Vermutung widerlegt. Kein Explorationsalgorithmus kann in Räumen
mit n Hindernissen einen kompetitiven Faktor erzielen, der besser
als  n ist. Diese untere Schranke
gilt sogar, wenn die Hindernisse Rechtecke sind.
n ist. Diese untere Schranke
gilt sogar, wenn die Hindernisse Rechtecke sind.
In der Praxis ist die Annahme, daß der Roboter beliebig weit in die Ferne sehen kann, nicht gerechtfertigt. Typischerweise hat ein Roboter nur einen Sichtradius von 3-6m. Diese Einschränkung kann man dadurch modellieren, daß man ein Gitter über die Szene legt (s. Abb. 2, rechter Teil). Ein Gitterknoten zusammen mit den adjazenten Kanten beschreibt dann den Sichtbereich des Roboters an einem Punkt der Szene. Die Umgebung ist vollständig exploriert, wenn jeder Knoten und jede Kanten des Graphen mindestens einmal besucht bzw. überstrichen wurde. Ziel ist es, die insgesamt benötigte Anzahl von Kantenüberstreichungen zu minimieren. Selbstverständlich erzielt eine Graphdurchmusterungstechnik wie Tiefensuche einen konstanten kompetitiven Faktor. Wir haben Algorithmen für Gitter mit beliebigen rechtwinkligen Hindernissen entwickelt, die einen konstanten kompetitiven Faktor erzielen und dabei die Piecemeal-Eigenschaft erfüllen. Diese Eigenschaft besagt, daß der Roboter in regelmäßigen Abständen, z.B. zum Auftanken, zu einem ausgezeichneten Startknoten zurückkehren muß.
Bei der graphentheoretischen Abstraktion der Szene kann man noch einen Schritt weiter gehen. Möchte man geometrische Eigenheiten der Umgebung vernachlässigen und sich ganz auf die kombinatorische Komplexität des Explorationsproblems konzentrieren, so kann man die Szene durch einen beliebigen gerichteten Graphen modellieren. Ziel ist es wieder, den Graphen mit so wenig Kantenüberstreichungen wie möglich zu explorieren. Zusammen mit einer Kollegin haben wir exponentielle Verbesserungen gegenüber bisher bekannten Lösungen vorgestellt.
5. Schlußbemerkungen
Die hier vorgestellten Probleme bilden nur eine kleine Auswahl von
Online-Problemen, die in der Forschung untersucht werden. In den vergangenen
Jahren sind zum Beispiel verschiedene finanzielle Spiele betrachtet worden.
Dort geht es unter anderem darum, ein Portfolio zusammenzustellen, ohne
zu wissen, wie sich beispielsweise Aktienkurse entwickeln. Die vorgestellten
Lösungen sind aber bisher nicht unmittelbar in der Praxis einsetzbar.
Darüber hinaus werden in der Forschung sogenannte Server- und
metrische Tasksysteme untersucht, die eine große Klasse von
Online-Problemen modellieren können.
Literatur
[ST85] Sleator, Daniel D.
and Tarjan, Robert E., Amortized efficiency of list update and paging
rules, Comm. of the ACM (1985) 202-208
[DKP98] Xiaotie Deng, Tiko Kameda, Christos
H. Papadimitriou: How to Learn an Unknown
Environment I: The Rectilinear Case. Journal of the ACM 45 (1998) 215-245
Adresse
Dr. Susanne Albers
Max-Planck-Institut für Informatik
Im Stadtwald
66123 Saarbrücken
Email: albers@mpi-sb.mpg.de
WWW: http://www.mpi-sb.mpg.de/~albers
Lebenslauf
Dr. Susanne Albers (33 Jahre) ist seit 1993 Mitglied der Forschungsgruppe
Algorithmen und Komplexität des Max-Planck-Instituts für Informatik
in Saarbrücken und hat seither auf ihrem Arbeitsgebiet eine ganze
Reihe bedeutender Forschungsergebnisse in den wichtigsten Zeitschriften
und auf den renommiertesten internationalen Tagungen der Theoretischen
Informatik veröffentlicht.
Frau Albers hat Mathematik und Informatik studiert und 1993 mit einer
Arbeit zum Thema "On the Influence of Lookahead in Competitive Online Algorithms"
promoviert. Auf ihre Promotion folgten ein einjähriger Forschungsaufenthalt
am ICSI-International Computer Science Institute an der Universität
Berkeley, USA, sowie weitere kurzzeitige Forschungsaufenthalte in Europa,
USA und Japan.
Im letzten Jahr war Frau Albers als Gastprofessorin an der Freien Universität
Berlin und der Universität Paderborn tätig. Anfang dieses Jahres
erhielt sie Rufe auf Professuren für Theoretische Informatik an der
Universität Paderborn und der Universität Trier.
Frau Albers erhielt 1994 die Otto-Hahn-Medaille für den wissenschaftlichen
Nachwuchs der Max-Planck-Gesellschaft, die für besondere Forschungsleistungen
im Rahmen der Dissertation verliehen wird.
|